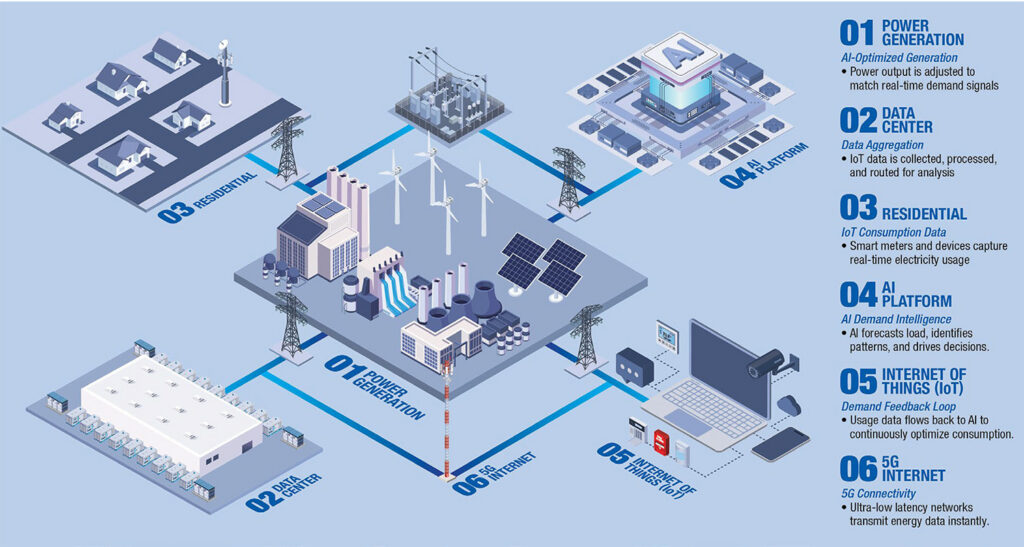
FS has launched an 800G AI networking solution aimed at NVIDIA B300 GPU clusters, built around a 51.2T RoCEv2 Ethernet architecture. The package is designed for large-scale AI training environments that need high bandwidth, low latency, and scalable lossless connectivity.
The FS B300 AI network solution is based on 800G Ethernet and a lossless spine-leaf fabric architecture. FS positions the design around the operational realities of large GPU clusters, where bandwidth, latency, congestion control, and horizontal scalability can become the limiting factors for overall training throughput and stability.
On the control and operations side, the solution uses the PicOS network operating system to provide consistent management across multi-device and multi-tier environments. FS says this is intended to improve network stability and security while simplifying version upgrades and maintenance. The solution also integrates AmpCon management software for data center networks, which FS says supports automated deployment, unified real-time monitoring, and standardized architecture management to improve visibility and reduce operational complexity.
For data center engineers building training fabrics, the practical point is that “lossless Ethernet” still lives or dies by congestion behavior and day-two operations. Features like PFC and DCQCN can help in RoCEv2 environments, but they also introduce tuning and troubleshooting work that teams need to be prepared to own across the full spine-leaf.
Technical highlights
FS lists the following capabilities for the B300 AI networking solution:
• 51.2T high-throughput network with multi-track optimization
• Scalability for large network deployments
• PFC, DCQCN, shared buffers, and intelligent load balancing for lossless networking
• A dedicated RDMA storage network intended to accelerate AI training
Source: FS