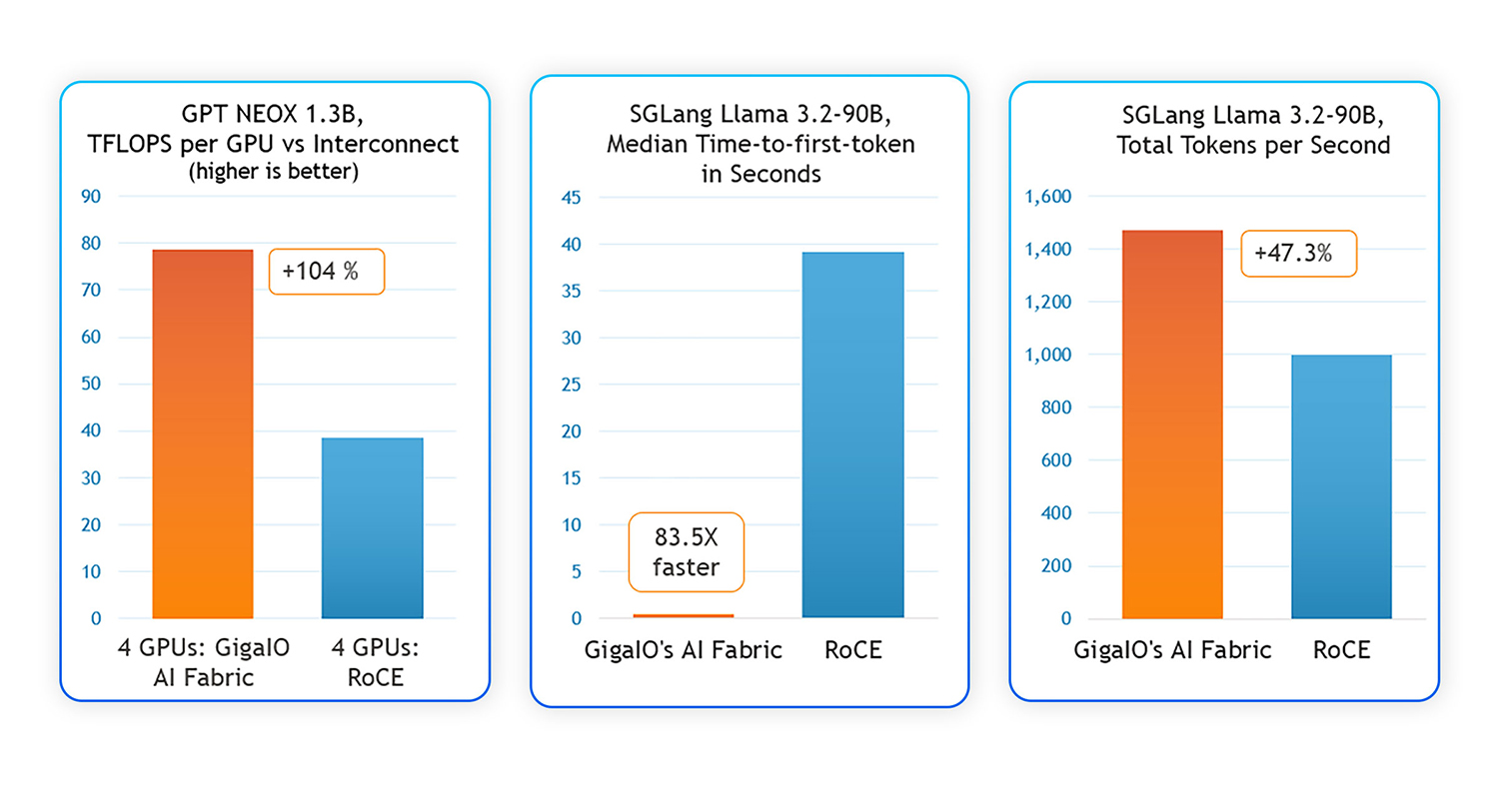
GigaIO has announced benchmark results demonstrating its AI fabric interconnect achieves significantly better performance, power efficiency, and deployment ease compared to traditional RDMA over Converged Ethernet (RoCE). The tests, conducted using identical GPUs, servers, operating systems, and AI software, show the PCIe-native GigaIO solution delivers two times the training and fine-tuning throughput, reduces inference time to first token by 83 times, and offers sustained hardware simplicity and lower power consumption.
According to GigaIO, its architecture achieves faster multi-GPU cluster setup and higher GPU utilization rates for AI training workflows. In distributed training scenarios, GigaIO’s AI fabric demonstrated 104% increased throughput compared to RoCE. For large AI model inferencing, such as the Llama 3.2-90B Vision Instruct model, GigaIO reduced time-to-first-token latency by 83.5 times, providing highly responsive performance for interactive AI applications, including chatbots, computer vision systems, and Retrieval Augmented Generation (RAG) pipelines.
Testing also highlighted power use and equipment efficiencies. GigaIO claims its AI fabric cuts overall power consumption by 35-40% relative to RoCE-based systems of equivalent performance by eliminating protocol overhead, streamlining hardware setups, and removing specialized tuning and additional networking hardware—including Ethernet switches and Network Interface Cards (NICs). As a result, users require 30-40% less hardware in GPU deployments for the same workloads.
“With GigaIO, we spend less time on infrastructure and more time optimizing LLMs,” said Greg Diamos, CTO of Lamini, an enterprise custom AI platform.
Further results showed 47.3% higher inference throughput and efficiencies permitting handling equivalent user loads with 30-40% fewer hardware resources than comparable RoCE deployments. Additionally, in a 16-GPU AMD MI300X cluster setup, the benchmarks indicated that GigaIO’s solution yielded a 38% higher training throughput and improved GPU usage, enabling accelerated convergence times for large models.
Source: GigaIO










