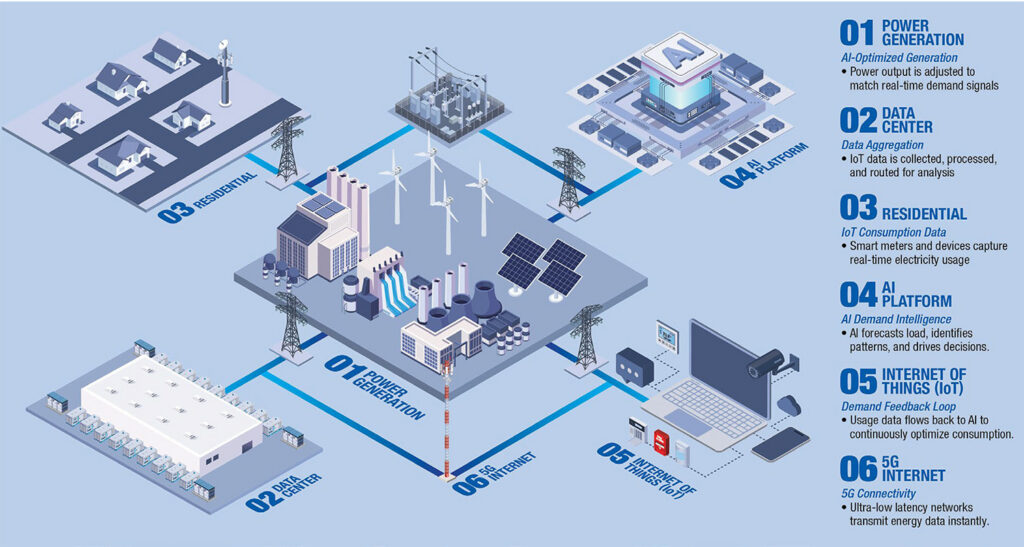
KAYTUS has launched an all-QLC flash storage solution aimed at feeding data to 10,000-GPU clusters, targeting read-heavy AI training environments where storage throughput and latency can cap GPU utilization. Introduced at AI EXPO KOREA 2026, the company frames the system as a way to remove data-delivery bottlenecks in ultra-large-scale training deployments.
The all-QLC flash storage solution is built on KAYTUS’s KR2280 and KR1180 server platforms and integrates with “industry-leading AI-native parallel file systems.” KAYTUS describes the design goal as avoiding data silos associated with tiered storage by tying compute nodes and the parallel file system more tightly together for read-intensive workloads.
In testing described for an exabyte-scale deployment, KAYTUS reports 10 TB/s aggregate bandwidth and 100 million IOPS. The company also claims a five-year TCO reduction of 70% versus traditional TLC-based solutions. Those are big numbers, but for data center operators the practical question is how repeatable they are once you layer in real-world network design, metadata behavior, and multi-tenant contention.
On the architecture side, KAYTUS says the system provides a unified namespace with native multi-protocol access across file, object, and block storage. It uses high-capacity QLC flash pools and NVMe-oF shared interconnects, with the goal of allowing data to flow to GPU nodes “on demand” without cross-system migration.
At the node level, KAYTUS says the design uses a PCIe 5.0 direct-connect architecture intended to double single-node I/O bandwidth compared to the previous generation, along with NUMA-balanced optimization to reduce internal throughput bottlenecks. On the data path, KAYTUS says it supports NFS over RDMA and native GPU Direct Storage, with a disaggregated design that decouples protocol processing from storage states to reduce east-west traffic.
KAYTUS also outlined a QLC product lineup with single-drive capacities up to 122.88 TB. KR1180 (1U10) is listed at 1 PB capacity and 140 GB/s bandwidth in 1U, with “optimized air cooling” and an 18% latency improvement under GPU workloads. KR2280 (2U24) supports 24 QLC drives and seven PCIe 5.0 slots, is compatible with Intel and AMD platforms, and has liquid-cooling options. KR4266 (4U60) is listed at up to 7 PB per unit, 260 GB/s sequential read bandwidth, and 20 million IOPS.
Source: KAYTUS