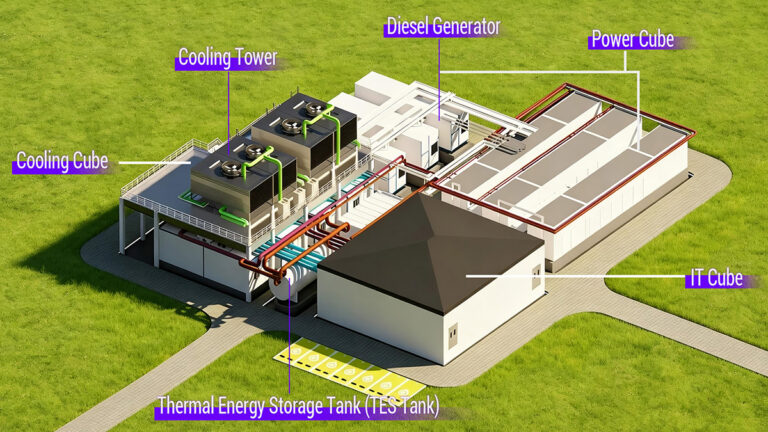
OpenAI and Broadcom have introduced Jalapeño, an OpenAI-designed “Intelligence Processor” aimed at LLM inference, and positioned as the first accelerator in a multi-generation compute platform the two companies are developing. OpenAI says it expects the platform to be deployed with data center partners at gigawatt scale over multiple generations.
OpenAI describes Jalapeño as a blank-slate design built for modern LLM inference rather than a general-purpose accelerator adapted from earlier AI workloads. The chip is intended to combine high throughput with lower latency for interactive LLM products, and is designed to work with “all LLMs,” guided by OpenAI’s view of current and future inference needs across the industry.
Engineering samples are running ML workloads in the lab at “production target frequency and power,” including GPT-5.3-Codex-Spark. OpenAI says it is still measuring final performance, but claims early testing indicates performance per watt “substantially better than current state-of-the-art.” OpenAI and Broadcom say a detailed technical report on performance is planned for the coming months.
On the systems side, OpenAI says Jalapeño’s architecture targets reduced data movement and a balance of compute, memory, and networking resources to push realized utilization closer to theoretical peak. Broadcom points to its silicon implementation and networking technologies, including Tomahawk networking silicon, as part of bringing the platform to large-scale production.
OpenAI and Broadcom also claim a fast development cycle: the companies say Jalapeño went from initial design to manufacturing tape-out in nine months, with OpenAI’s models used to accelerate parts of the design and optimization process. Celestica is named as a partner supporting industrialization work including chip implementation, board and rack system integration, high-performance networking, and scalable production systems.
For data center engineers, the headline implication is simple: if Jalapeño’s performance-per-watt claims hold up in independent, workload-relevant measurements, it could shift the power envelope for LLM inference clusters. But until that promised technical report lands, operators are left with architecture-level intent and early lab results, not deployment-grade sizing data.
“We optimized the architecture around the kernels, memory movement, networking, and serving patterns that matter most for frontier AI models,” said Richard Ho, who leads OpenAI’s hardware program. Hock Tan, Broadcom president and CEO, said the roadmap is “beginning in 2026,” and referenced “deployment of gigawatt scale data centers with Microsoft and other partners.”
Source: Broadcom