KAYTUS used ISC 2026 to launch KSManage Ultra, an infrastructure management platform the company says is built for “AI Factories” and rack-scale AI deployments. The pitch is straightforward: consolidate visibility and control across GPUs, racks, and the data center so operators can find bottlenecks faster and keep high-density systems running consistently.
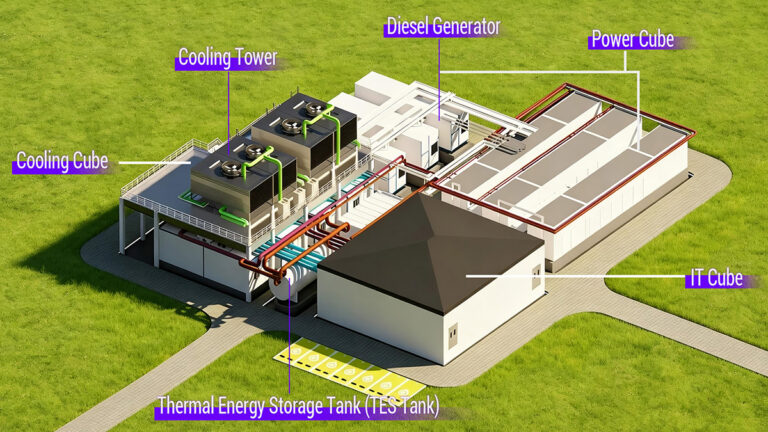
KSManage Ultra is designed to manage rack-level components as a single operational unit, including compute trays, switch trays, PDUs, and CDUs. KAYTUS is targeting the shift from server-level administration to tightly coupled rack systems where computing, networking, power, and liquid cooling are interdependent, and a problem in any subsystem can ripple into application performance.
On the monitoring side, the platform combines in-band telemetry (operating systems, drivers, applications, and performance) with out-of-band data (BMC, firmware, power, temperature, and hardware logs), plus broader infrastructure data, in one management system. KAYTUS says KSManage Ultra correlates operating status, hardware health, link topology, power supply, and liquid-cooling conditions, aiming to move operations from reactive response to proactive alerting.
For liquid-cooling operations, KSManage Ultra includes what KAYTUS describes as three-level leak detection at the node, rack, and loop levels. When a leakage risk is detected, the platform can coordinate safety shutdown, solenoid valve closure, and node isolation, and it can also trigger email alerts, work order generation, and “closed-loop remediation.”
KSManage Ultra is also positioned as a health and fault-isolation layer for multi-rack deployments. KAYTUS says it continuously evaluates node and rack health using indicators including GPU status, memory and PCIe status, network link quality, firmware consistency, liquid-cooling conditions, and power supply status. When it detects abnormal nodes or high-risk components, the system can apply tagging, analyze impact scope, and initiate isolation actions to keep questionable nodes out of critical training or inference runs.
But the most concrete operational claim is around provisioning speed. KAYTUS says KSManage Ultra supports one-click batch scanning and automatic node addition, using device serial numbers and IP addresses to build topology mappings between nodes and racks. The company says this cuts single-rack onboarding time from 50 minutes to less than 3 minutes. It also claims one-click batch stress testing at “L10 and L11” levels can reduce fault root-cause localization from hours to minutes, and it supports rack-level automated initialization and configuration including driver installation, hardware configuration, and software deployment via templates.
KSManage Ultra includes open APIs intended to integrate with systems such as schedulers and CMDBs, while also managing heterogeneous lower-layer devices including servers, networking equipment, power infrastructure, and cooling systems. In high-density racks where a lot can go wrong without a clean signal path between IT telemetry and facility conditions, that full-stack correlation claim is the real make-or-break feature.
Source: KAYTUS